LHC 빅데이터에서의 딥러닝과 인공지능 기술의 새로운 요구사항 – 해석가능성
LHC 가속기는 질량의 근본을 설명하는 힉스 보존의 존재를 2013년도에 최종적으로 확인하여 목표로 했던 가장 중요한 미션은 완수하였으나, 힉스 보존 존재를 확인함으로써 다시 규명해야 할 중요하고 다양한 과학적 질문들이 새로운 숙제로 남게 되었다. 이를 위해 CERN과 전 세계 LHC 공동 연구단은 LHC 가속기의 양성자빔 광도(luminosity)를 높여 더 많은 이벤트를 발생시켜 입자물리학적 현상을 정밀하게 규명할 수 있도록 업그레이드를 준비 중이다.
업그레이드될 LHC 가속기를 고광도 LHC(High-Luminosity LHC; HL-LHC), 또는 슈퍼 LHC(Super-LHC)라고 부른다. HL-LHC로 LHC 가속기가 업그레이드되면 검출기에서 발생하는 데이터의 양이 기하급수적으로 증가하게 되는데, 2019년에는 2016년에 생성된 데이터의 4배에 이르는 293PB, 2028년에는 2016년에 생성된 데이터의 52배에 이르는 3.8EB에 이를 것으로 추정된다. 이렇게 많은 데이터를 추정하기 위해 현재 LHC의 네 개의 검출기 시스템에 쓰이고 있는 이벤트 데이터 가공 자동화 시스템과 소프트웨어를 전면적으로 개선하는 작업이 현재 진행되고 있다.

현재 데이터보다 수십 배 이상 쏟아져 나오는 데이터를 놓치지 않고 처리하여 중요한 물리학적 단서들을 포착하기 위해 이벤트 데이터를 현재보다 정밀하고 빠르게 분석, 가공하는 기술이 필요하다. 이를 위해 LHC 연구자들은 최근 주목을 받는 딥러닝 기술을 활용해서 보다 더 정밀하고 빠르게 이벤트 데이터를 분석할 수 있는 다양한 방법과 분석 기법에 대한 연구결과를 발표하고 있다.
최근 딥러닝을 이용해 LHC 데이터를 분석한 결과 중 많은 관심을 모았던 것은 딥러닝을 이용해 힉스 보존이 생성되는 이벤트와 힉스 보존 이벤트와 같은 입자들을 생성하지만 힉스 보존 때문에 생기는 것이 아닌 다른 배경 이벤트들을 구분하는 이벤트 분류기를 만드는 데에 딥러닝 기술을 적용한 연구 결과이다.
어바인 소재 캘리포니아 주립대(University of California, Irvine)의 피터 사도프스키(Peter Sadowski)와 피에르 발디(Pierre Baldi) 교수, 줄리안 콜라도(Julian Collado), 다니엘 화이트슨(Daniel Whiteson)은 2014년 고에너지 물리학에서의 머신러닝 응용을 논의하는 학술회의인 HEPML 2014에서 딥러닝을 이용해 힉스 보존을 생성하는 이벤트와 그 외 배경 이벤트를 구분하는 분류기(classifier) 모델을 딥러닝으로 만들어 그 성능이 기존의 분류기보다 더 높아지는 것을 보였다[2-6].
피터 사도프스키와 공동 연구진은 물리학적으로 정의된 21개의 저수준(low-level) 자질(feature) 벡터와 7개의 고수준(high-level) 자질(feature) 벡터를 이용해 힉스 입자 이벤트와 그 외 이벤트를 분류하는 딥러닝 모델을 만들고, Pythia와 같은 이벤트 시뮬레이션 소프트웨어를 통해 메타데이터가 붙여진 이벤트 실험 데이터를 이용해 딥러닝 모델을 학습시켰다. 이 딥러닝 모델의 분류 성능을 과거 물리학적 지식을 이용한 분류기 알고리즘의 이벤트 분류 성능과 비교하였다. 그 결과 딥러닝을 이용한 이벤트 분류기 성능이 더 높게 나타났다(그림 1).
피터 사도프스키와 공동 연구진의 딥러닝을 응용한 힉스 보존 이벤트 분류기 실험 결과에서 주목해야 할 결과는 딥러닝 모델이 위에서 언급한 28개의 자질(feature) 벡터를 모두 사용하지 않더라도 힉스 보존을 구분할 수 있는 분류기 모델을 잘 학습했다는 것이다. 위에서 언급한 7개의 고수준 자질 벡터는 21개의 저수준 자질 벡터를 이루는 물리학적 변수들로부터 유도가 가능한 물리학적 변수들로, 분류기 모델의 정확도를 보조하는 역할을 하는 변수들이었다. 기존의 이벤트 분류기 모델은 물리학적 변수를 이용한 자질 벡터가 많을수록 분류기의 성능이 더 좋아졌지만, 딥러닝을 이용한 분류기 모델은 21개의 저수준 자질 벡터만 이용하여 기존 입자 물리학적 지식을 이용한 분류기 알고리즘보다 더 높은 성능을 얻을 수 있었다[2-6].
피터 사도프스키와 공동 연구진이 밝혀낸 또 하나의 중요한 과학적 기여는 바로 앙상블(ensemble) 심층 신경망(deep neural network) 모델의 ‘지식 증류(Knowledge Distillation)’ 방법을 통해서 계산량이 적으면서도 힉스 입자 이벤트 분류 성능이 좋은 신경망 모델을 만들 방법을 찾아낸 것이다. 이들은 성능이 좋은 심층 신경망(deep neural network) 모델이 학습한 이벤트 분류의 ‘숨은 지식(dark knowledge)’을, 심층 신경망(deep neural network) 모델보다 계산량이 적은 얕은 신경망(shallow neural network)이 학습, 전수받도록 하여 계산량이 적으면서도 분류 성능이 더 좋은 신경망 모델을 만드는 것이 가능하다는 것을 확인하였다[2, 5].
딥러닝 분야에서 유명한 연구자들인 제프리 힌튼(Geoffrey Hinton), 오리올 비니얄즈(Oriol Vinyals), 제프 딘(Jeff Dean)은 2014년 신경정보처리시스템(Neural Information Processing Systems; NIPS) 학술대회에서 함께 열린 ‘딥러닝 및 표상 학습 워크숍(NIPS Deep Learning and Representation Learning Workshop)’에서 신경망에서의 ‘지식 증류’를 이용한 분류 성능 향상 방법을 발표하였다. ‘지식 증류’ 방법은 특정한 카테고리의 데이터만 집중적으로 학습한 ‘전문가(expert)’ 신경망들의 앙상블이 가진 소위 ‘숨은 지식’을 전문가 신경망 앙상블보다 계산량이 적고 구조가 단순한 얕은 신경망으로 전달하는 방법이다.
제프리 힌튼(Geoffrey Hinton), 오리올 비니얄즈(Oriol Vinyals), 제프 딘(Jeff Dean)은 전문가 신경망들이 학습할 때 배운 ‘숨은 지식’이 정답과 함께 소프트맥스(softmax) 함수값으로 주어지는 좀더 부드러운 형태의 출력값으로 표현된 학습 데이터를 이용해 전문가 신경망들을 함께 사용하여 얕은 신경망을 학습시키면, 얕은 신경망만을 학습시킬 때보다 더 성능이 좋아진다는 것을 발견했다.
피터 사도프스키와 공동 연구자들은 이런 지식 증류 방법을 힉스 입자 분류 작업에 똑같이 적용해보았고 역시 얕은 신경망 모델의 힉스 입자 이벤트 분류기의 성능이 더 좋아지는 것을 확인했다. 이 결과는 검출기의 실시간 데이터 처리 시스템에서 힉스 입자 검출, 분류를 신경망 모델을 사용해서 좀더 적은 계산량으로 더 정확하게 할 수 있는 방법을 찾은 것이어서 LHC 연구자들에게 중요한 결과로 받아들여졌다.
피터 사도프스키와 공동 연구자들이 힉스 입자 검출, 분류에 지식 증류 방법을 적용한 결과의 또 다른 중요성은 바로 힉스 입자를 분류하는 신경망 모델이 어떻게 힉스 입자를 분류하는지 해석할 수 있는 방법의 하나를 찾은 것이다.
딥러닝 모델의 가장 큰 문제점 중의 하나는 모델의 파라미터 수가 많고 복잡하여 딥러닝 모델이 학습한 작업을 수행할 때 어떤 방식으로 작업을 수행하고 출력값을 내는지 이해하고 해석하기가 어렵다는 것이다. 이런 딥러닝 모델의 해석가능성(interpretability) 문제는 최근 딥러닝 기술이 사람들의 생활에 영향을 줄 수 있는 추천 시스템, 질병 진단 시스템 등의 의사 결정 및 판단 자동화 분야에 적용되기 시작하면서 점차 중요하게 인식되고 있다.
하나의 딥러닝 모델이 힉스 입자 이벤트 분류를 학습하게 되면 입력된 이벤트 데이터를 어떤 과정을 거쳐 힉스 입자 이벤트로 분류했는지 물리학적인 해석을 하기가 어렵다. 하지만, 특정한 카테고리별, 또는 힉스 입자 생성 이벤트별 데이터를 전문적으로 학습한 ‘전문가 신경망’들의 지식을 전달받은 하나의 심층 신경망 모델은 전문가 신경망들이 어떤 이벤트들을 분류하는지 우리가 알고 있기 때문에 좀더 해석가능한(interpretable) 신경망 모델이 된다. 이렇게 전문가 신경망들이 분류하는 대상과 방식이 지식 전수 형태로 전달된 심층 신경망의 해석가능성이 딥러닝 기술로 분류된 힉스 입자 이벤트를 좀더 정밀하게 검증하고 그 배경이 되는 물리학적인 현상을 깊게 이해할 수 있도록 돕게 된다.
이번에는 LHC 검출기에서 나오는 제트(jet) 이벤트 검출 및 분류 자동화에 딥러닝 모델을 응용한 사례를 하나 더 살펴보도록 하자. 제트란 높은 에너지로 가속된 입자들이 제한된 단면적의 공간으로 한꺼번에 쏟아져 나오는(shower) 현상을 말한다. 입자물리학적으로 좀더 정확하게 얘기하면, 쿼크(quark)나 글루온(gluon)같이 높은 에너지 상태로 갇혀 있던 근본 입자들이 강입자(hadron)로 붕괴, 변화되면서 변화된 강입자와 관련된 다른 입자들이 콘(cone), 또는 고깔모자와 같은 형태로 쏟아져 나오는 현상을 말한다.
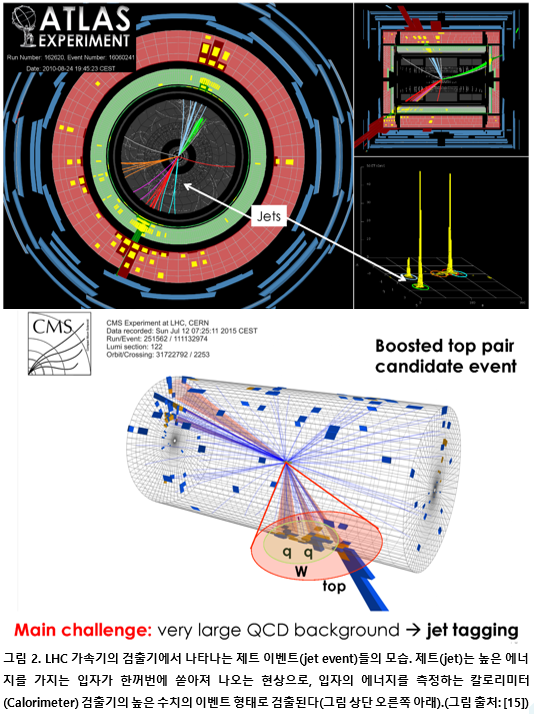
이런 제트 이벤트들은 힉스 보존과 같이 특정한 근본 입자와 관련된 이벤트에 따라 그 특성이 달라진다. LHC 각 검출기의 상호작용 지점(interaction point)에서 일어난 이벤트 중에서 힉스와 같이 관심 있는 입자들의 생성과 물리학적 특성을 간접적으로 관찰, 조사하기 위해 잘 활용되는 이벤트이다.
제트 이벤트는 강입자(hadron)들의 에너지를 측정하는 칼로리미터 검출기에서 수집된 영상 데이터에서 높은 에너지를 가지는 픽셀군의 형태로 잘 검출이 된다. 그림 2의 상단에 보면, 그림의 오른쪽 아래에 좁은 영역에 높은 에너지의 이벤트로 검출된 제트 이벤트를 볼 수 있다. 이렇게 칼로리미터에서 관찰되는 제트 이벤트를 ‘칼로리미터 타워(calorimeter tower)’라고 하는데, 칼로리미터 타워로 검출되는 제트 이벤트를 분석하면 힉스 입자와 같은 근본 입자가 생성되었는지 확인할 수 있다. 그림 2의 하단에서도 CMS 검출기의 이벤트 재구성 데이터에서 콘 형태로 검출된 W입자의 제트(W-like jet)와 QCD 배경 제트(QCD background jet)을 볼 수 있다.
보통 칼로리미터의 검출 원리와 픽셀의 해상도를 고려하면 위와 같은 W 입자 제트와 QCD 배경 제트를 정확하게 구분하기가 쉽지 않다. 제트 이벤트의 물리학적 메커니즘에 대해서는 상대적으로 많은 연구가 이루어져 있기는 하지만[10-12], 이런 이론적인 연구 결과를 활용해서 정확하게 제트 이벤트를 분류, 검출하는 소프트웨어 기술은 아직 개발되지 않았다[13].

위와 같이 칼로리미터 데이터를 이용해 제트 이벤트를 분류하는 기술을 입자 물리학자들은 ‘제트 태깅(Jet tagging)’이라고 부른다. 최근 제트 태깅 문제에 딥러닝을 적용하여 성능을 향상한 결과를 발표한 연구 결과가 다수 있었다[15-17]. 예일 대학교의 미켈라 파가니니(Michela Paganini) 박사는 보텀 쿼크 입자의 제트 이벤트를 분류하는 ‘보텀 쿼크(bottom quark) 제트 태깅’ 문제에 딥러닝을 적용하여 보텀 쿼크 태깅 성능을 높인 결과를 미국 시애틀에서 열린 국제 물리학 고등 컴퓨팅 및 분석 기술 학술회의(International Workshop on Advanced Computing and Analysis Techniques in Physics Research; ACAT 2017)에서 발표하였다[17].
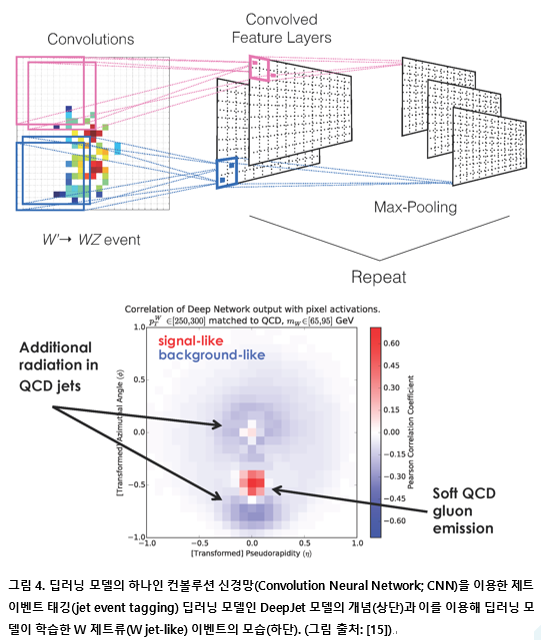
미켈라 파가니니 박사의 보텀 쿼크 태깅 문제에 딥러닝 기술을 적용한 결과가 발표되기 전인 2016년, 딥러닝 기술을 W입자 제트 태깅 문제에 적용하여 제트 이벤트 분류 성능을 크게 높인 결과가 스탠퍼드 대학의 루크 드 올리비에라(Luke de Oliveira), 마이클 케이건(Michael Kagan), 레스터 맥케이(Lester Mackey), 벤자민 나크만(Benjamin Nachman), 에어리얼 슈바르츠만(Ariel Schwartzman)에 의해 칠레의 밸파라디소에서 열린 ACAT 2016 학술회의에서 발표되었다[15-16]. 여기서는 이들이 발표한 W 입자 제트 태깅 결과를 간단하게 소개해보고자 한다.
루크 드 올리비에라와 그의 동료 연구자들이 만든 딥러닝 기반의 제트 이벤트 분류 기술은 우선 칼로리미터 데이터를 이미지화하는 전처리 과정을 통해 칼로리미터 타워가 픽셀의 컬러값으로 변환되는 이미지로 만든다(그림 3 좌편). 이렇게 만들어진 제트 이벤트의 칼로리미터 이미지를 그림 4에 나타난 컨볼루션 신경망(Convolution Neural Network) 기반의 딥제트(DeepJet)라는 딥러닝 모델을 학습시키는 데 사용한다. 학습된 신경망의 마지막 출력층에서 각 픽셀의 최대값 선택(max pooling) 과정을 거치면 그림 4의 하단에 나온 것과 같이 피셔 변환을 통해 구분된 QCD 배경 제트 이벤트의 이미지와 W입자 제트 이벤트의 이미지와 유사하게 제트 이벤트 태깅된 이미지를 심층신경망이 출력으로 내놓게 된다.
그림 5는 딥제트(DeepJet) 딥러닝 모델의 성능을 과거 피셔 변환 및 물리학적 알고리즘 기반의 제트 이벤트 태깅 모델의 성능과 비교한 것이다. 놀랍게도, 딥러닝 모델이 분류한 제트 이벤트 태깅 성능이 과거 피셔 변환 및 물리학적 알고리즘 기반의 ‘N-서브제티니스(n-subjettiness)’ 방법으로 제트 이벤트 태깅을 한 결과보다 2배 이상의 높은 정확도를 보였다. 또한, 제트 이벤트의 칼로리미터 이미지를 입자의 질량과 같은 물리학적 변수를 같이 자질(feature)로 사용하여 학습시킨 ‘N-서브제티니스(n-subjettiness)’ 모델을 사용하면 ‘N 서브제티니스(n-subjettiness)’ 모델의 분류 성능이 좀더 향상되지만, 그렇다고 하더라도 여전히 딥러닝 기반의 딥제트(DeepJet)의 분류 성능과 2배 가까운 차이가 났다(그림 5).
그림 5의 결과를 보면 제트 이벤트의 칼로리미터 데이터를 이미지로 변환하여 딥러닝 기술을 활용할 경우 더 정확하게 우리가 원하는 이벤트를 분류할 수 있다는 것을 알 수 있다. 또한, 물리학적 변수들을 자질로 활용한 과거 머신러닝 기반의 제트 이벤트 태깅 알고리즘과 비교하면 딥러닝 기술이 더 정확한 결과를 내는 것으로 보아 제트 이벤트 태깅을 위해 데이터를 학습한 딥제트(DeepJet) 모델이 물리학적인 숨은 지식을 같이 학습하여 제트 이벤트 태깅의 정확도를 높인다고 볼 수 있다.
위의 힉스 보존 이벤트 분류 및 제트 이벤트 태깅 문제에 딥러닝 기술을 적용한 결과는 LHC 빅데이터 처리 성능 향상에 또다른 돌파구를 마련해 주었지만, LHC 연구자들에게 또 다른 숙제가 남게 되었다. 과연 딥러닝 모델이 어떤 물리학적인 숨은 지식을 더 학습하여 과거의 물리학적인 이벤트 분류 알고리즘보다 더 나은 성능을 보인 것인가? 이렇게 딥러닝 모델이 학습한 물리학적인 숨은 지식이 정말 실제 물리학적 현상으로 일어날 수 있고 의미 있는 지식인가? 딥러닝 모델이 데이터로부터 학습한 이런 숨은 지식이 물리학적으로 의미하는 것은 무엇인가? 이렇게 딥러닝 모델이 학습한 검출기 이벤트에 대한 지식을 물리학자들이 물리학적으로 활용하여 과거에 알지 못했던 새로운 입자의 검출과 입자 물리학적 현상 분석에 활용할 수 있을까? 딥러닝 모델이 학습한 지식을 LHC 연구자들이 과연 어떤 방법으로 보고 해석할 수 있을까?

딥러닝 모델을 이용해 이벤트 데이터를 분석한 결과는 놀라운 성능을 보여주었지만, LHC 연구자들이 LHC 데이터에서 보지 못하는 것이 아직도 많음을 또한 알게 해주었다. 지금보다 52배 이상 더 많은 데이터가 쏟아져 나오는 고광도 LHC(HL-LHC; Super-LHC) 시대에는 딥러닝 기술을 활용한 이벤트 자동 분류 기술이 더 중요해질 것이며, 딥러닝 기술을 통해 더 많은 물리학적 지식과 통찰을 얻을 수 있을 것으로 물리학자들은 기대하고 있다. 딥러닝 기술이 LHC 이벤트 데이터 분석에 적용되는 것은 이제 막 시작 단계로 앞으로 더 많은 흥미로운 연구 결과들이 딥러닝을 비롯한 인공지능 기술을 통해 밝혀질 것으로 기대된다.
원문보기:
http://www.ciokorea.com/news/39367#csidx4fc6d01009922a1877930f699846bf5 
'NEWS' 카테고리의 다른 글
| AI 반도체 기업, M&A로 빠르게 기술 흡수…인재 확보 (0) | 2019.02.24 |
|---|---|
| 김진철의 How-to-Big Data | 빅데이터와 인공지능 (4) (0) | 2019.02.24 |
| 김진철의 How-to-Big Data | 빅데이터와 인공지능 (2) (0) | 2019.02.24 |
| 김진철의 How-to-Big Data | 빅데이터와 인공지능 (1) (0) | 2019.02.24 |
| VISION 2018이 주목한 제품은? (0) | 2019.02.24 |